Getting ArXiv Sanity Papers Via RSS
I like reading papers on arXiv, but I like discovering them more through Andrej Karpathy’s arxiv-sanity-lite. The little challenge with the latter is that there is no way to get those papers in a RSS feed, that I can then hook up to an RSS reader, like feedly or NetNewsWire if you’re on a MacOS machine.
So, as a starting step, I thought I’d try and fix this with an open-source project, called arxiv-sanity-feeds. The idea is very simple - there is a GitHub Action job that runs daily and scrapes the content from arxiv-sanity-lite. The scraper is a Python script that reads the content and re-structures it into a RSS feed. That feed is then published on my DigitalOcean Spaces bucket, from where it can be consumed by anyone around the globe.
But hold on - does that mean that there is an API that I can tap into? Kind of. What Andrej did for his project is expose every paper that is in the view in JSON format. So, let’s say you see this page:
If you view the source through your browser, you might notice this little snippet that will end up being very helpful for any future exploration:
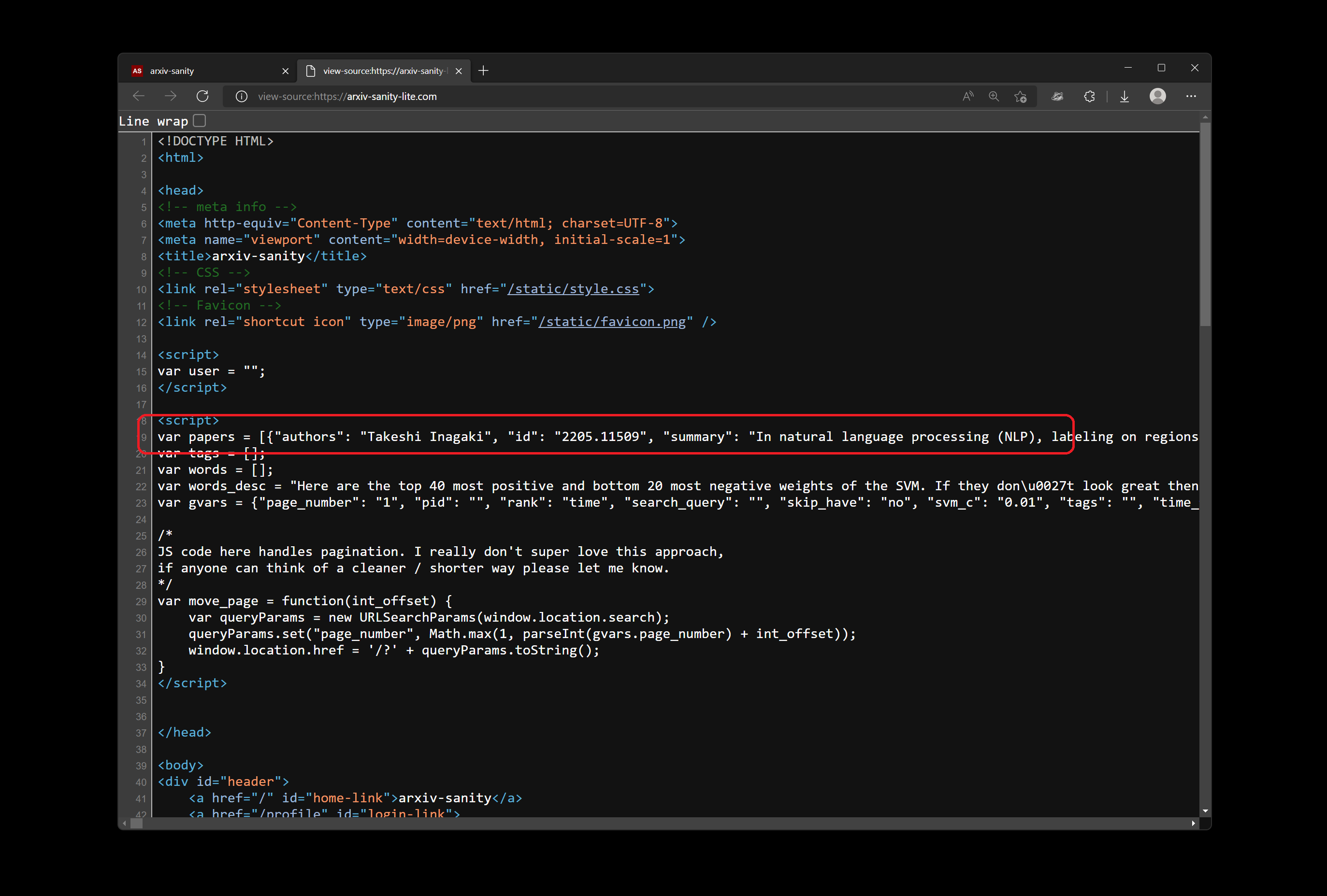
The entire page is represented as structured JSON, so I don’t really need to fiddle with HTML parsing, which is a can of worms I try to delay opening as much as possible. If I beautify this JSON, it will look like this (I trimmed the full text a bit):
[
{
"authors": "Takeshi Inagaki",
"id": "2205.11509",
"summary": "In natural language processing (NLP), labeling on regions of text, such as\nwords, sentences and paragraphs, is a basic task. In this paper, label is\ndefined as map between mention of entity in a region on text and context of\nentity in a broader region on text containing the mention. This definition\nnaturally introduces linkage of entities induced from inclusion relation of\nregions, and connected entities form a graph representing information flow\ndefined by map. It also enables calculation of information loss through map\nusing entropy, and entropy lost is regarded as distance between two entities\nover a path on graph.",
"tags": "cs.CL, cs.AI, cs.LG",
"thumb_url": "static/thumb/2205.11509.jpg",
"time": "May 23 2022",
"title": "Information Propagation by Composited Labels in Natural Language\n Processing",
"utags": [],
"weight": 0.8466816017059265
},
{
"authors": "Randall Balestriero, Yann LeCun",
"id": "2205.11508",
"summary": "Self-Supervised Learning (SSL) surmises that inputs and pairwise positive\nrelationships are enough to learn meaningful representations. Although SSL has\nrecently reached a milestone: outperforming supervised methods in many\nmodalities... the theoretical foundations are limited, method-specific, and\nfail to provide principled design guidelines to practitioners. In this paper,\nwe propose a unifying framework under the helm of spectral manifold learning to\naddress those limitations. Through the course of this study, we will rigorously\ndemonstrate that VICReg, SimCLR, BarlowTwins et al. correspond to eponymous\nspectral methods such as Laplacian Eigenmaps, Multidimensional Scaling et al.\nThis unification will then allow us to obtain (i) the closed-form optimal\nrepresentation for each method, (ii) the closed-form optimal network parameters\nin the linear regime for each method, (iii) the impact of the pairwise\nrelations used during training on each of those quantities and on downstream\ntask performances, and most importantly, (iv) the first theoretical bridge\nbetween contrastive and non-contrastive methods towards global and local\nspectral embedding methods respectively, hinting at the benefits and\nlimitations of each. For example, (a) if the pairwise relation is aligned with\nthe downstream task, any SSL method can be employed successfully and will\nrecover the supervised method, but in the low data regime, SimCLR or VICReg\nwith high invariance hyper-parameter should be preferred; (b) if the pairwise\nrelation is misaligned with the downstream task, BarlowTwins or VICReg with\nsmall invariance hyper-parameter should be preferred.",
"tags": "cs.LG, cs.AI, cs.CV, math.SP, stat.ML",
"thumb_url": "static/thumb/2205.11508.jpg",
"time": "May 23 2022",
"title": "Contrastive and Non-Contrastive Self-Supervised Learning Recover Global\n and Local Spectral Embedding Methods",
"utags": [],
"weight": 1.0686954905948152
},
{
"authors": "Dongruo Zhou, Quanquan Gu",
"id": "2205.11507",
"summary": "Recent studies have shown that episodic reinforcement learning (RL) is not\nmore difficult than contextual bandits, even with a long planning horizon and\nunknown state transitions. However, these results are limited to either tabular\nMarkov decision processes (MDPs) or computationally inefficient algorithms for\nlinear mixture MDPs. In this paper, we propose the first computationally\nefficient horizon-free algorithm for linear mixture MDPs, which achieves the\noptimal $\\tilde O(d\\sqrt{K} +d^2)$ regret up to logarithmic factors. Our\nalgorithm adapts a weighted least square estimator for the unknown transitional\ndynamic, where the weight is both \\emph{variance-aware} and\n\\emph{uncertainty-aware}. When applying our weighted least square estimator to\nheterogeneous linear bandits, we can obtain an $\\tilde O(d\\sqrt{\\sum_{k=1}^K\n\\sigma_k^2} +d)$ regret in the first $K$ rounds, where $d$ is the dimension of\nthe context and $\\sigma_k^2$ is the variance of the reward in the $k$-th round.\nThis also improves upon the best-known algorithms in this setting when\n$\\sigma_k^2$\u0027s are known.",
"tags": "cs.LG, math.OC, stat.ML",
"thumb_url": "static/thumb/2205.11507.jpg",
"time": "May 23 2022",
"title": "Computationally Efficient Horizon-Free Reinforcement Learning for Linear\n Mixture MDPs",
"utags": [],
"weight": 1.0688575276318522
}
]
This is wonderful, because my parser can now extract structured data and simply assign it to proper nodes that make up the final RSS feed. You can see the code in action on GitHub. When that part of the process is complete, I am using the boto3 library (DigitalOcean Spaces mirrors the AWS S3 API surface) to push the content to a pre-defined bucked that is already connected to a CDN and my custom domain.
If you view the arxiv-sanity-feeds README file, you’ll see quick links to all available feeds that you can subscribe to:

Or you can just click them from this blog:
- Home page feed - this is what gets rendered when you go to arxiv-sanity-lite.
- Most recent papers for the week
- Random papers from last week
As part of the process, I also wanted to make sure that I validate the feeds. W3C offers a validator, but there is no API so I wrapped the call to the web service in a GitHub Action that boils down to this Bash script:
#!/bin/bash
if curl "https://validator.w3.org/feed/check.cgi?url=${FEED_URL}" | grep "This is a valid RSS feed."
then
echo "The feed is valid."
exit 0
else
echo "The feed is invalid."
exit 1
fi
It’s a crude way to check if the response contains markers of a valid feed, and fail or succeed based on this data. This job is also scheduled to make sure that every generated feed is automatically verified for issues.
Any feedback on the tool is welcome - just open an issue in the repo. At some point I might consider extending this API with a serverless component, that enables passing through query parameters (e.g., if you are interested in just ML papers), but that’s for another blog post.